
1️⃣ 미분(differentiation)
- 변수의 움직임에 따른 함수값의 변화를 측정하기 위한 도구
- 편미분(partialdifferentiation)
- 벡터가 입력인 다변수 함수의 경우 사용
2️⃣ 경사하강법(gradient descent)
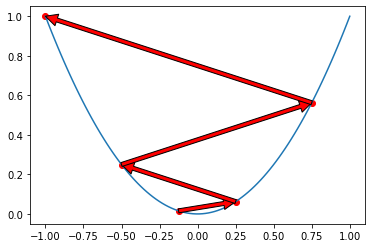
1) 경사하강법
- 함수의 극소값의 위치를 구할 때 사용
- 목적함수를 최소화할 때 사용
- 이론적으로 미분가능하고 볼록(convex)한 함수에 대해선 적절한 학습률과 학습횟수를 선택했을 때 수렴 보장
- 한 번 업데이트할 때마다 전체 데이터를 미분해야 함
- ↔ 경사상승법(gradient ascent) : 목적함수를 최대화할 때 사용
2) 파라미터
① 학습률 : 어느 만큼 이동시킬지 정해주는 것
미분을 통해 업데이트하는 속도 조절. 조심해서 다뤄야 함.
3) 알고리즘
var = init
grad = gradient(var)
while(abs(grad) > eps):
var = var - lr * grad
grad = gradient(var)- init :시작점
- lr : 학습률
- eps : 알고리즘 종료조건 → 컴퓨터로 계산할 때 미분이 정확히 0이 되는 것은 불가능하므로 eps 보다 작을 때 종료
3️⃣ 확률적 경사하강법(stochastic gradient descent)
1. SGD
1) SGD
- 모든 데이터를 사용해서 업데이트하는 대신 데이터 한개 또는 일부 활용하여 업데이트
- 볼록이 아닌 목적식은 SGD 를 통해 최적화 가능
- 따라서 경사하강법보다 머신러닝 학습에 더 효율적
- 원리 : 미니배치 연산
2) 장단점
- 장점 : 더 빨리, 자주 업데이트를 하는 것이 가능해짐
- 단점 : 랜덤 데이터를 사용하여 중간 결과의 진폭이 크고 불안정해 보일 수도 있음

2. 모멘텀(momentum)
- ‘관성, 탄력, 가속도’라는 뜻
- 경사 하강법에 탄력을 더해 주는 것. 오차를 수정하기 전 바로 앞 수정 값과 방향(+, -)을 참고하여 같은 방향으로 일정한 비율만 수정
- 수정 방향이 양수(+) 방향으로 한 번, 음수(-) 방향으로 한 번 지그재그로 일어나는 현상이 줄고, 이전 이동 값을 고려하여 일정 비율만큼만 효과를 냄.

3. 다른 방법
| 고급 경사 하강법 | 개요 | 효과 | 케라스 사용법 |
| 확률적 경사 하강법(SGD) | 랜덤하게 추출한 일부 데이터를 사용해 더 빨리, 자주 업데이트를 하게 하는 것 | 속도 개선 | keras.optimizers.SGD(lr = 0.1) 케라스 최적화 함수 이용 |
| 모멘텀(Momentum) | 관성의 방향을 고려해 진동과 폭을 줄이는 효과 | 정확도 개선 | keras.optimizers.SGD(lr = 0.1, momentum = 0.9) |
| 네스테로프 모멘텀 (NAG) | 모멘텀이 이동시킬 방향으로 미리 이동해서 그레이디언트를 계산. 불필요한 이동을 줄이는 효과 | 정확도 개선 | keras.optimizers.SGD(lr = 0.1, momentum = 0.9, nesterov = True) |
| 아다그라드 (Adagrad) | 변수의 업데이트가 잦으면 학습률을 적게 하여 이동 보폭을 조절하는 방법 | 보폭 크기 개선 | keras.optimizers.Adagrad(lr = 0.01, epsilon = 1e - 6) ※ 참고: 여기서 epsilon, rho, decay 같은 파라미터는 바꾸지 않고 그대로 사용하기를 권장하고 있습니다. 따라서 lr, 즉 learning rate(학습률) 값만 적절히 조절하면 됩니다. |
| 알엠에스프롭 (RMSProp) | 아다그라드의 보폭 민감도를 보완한 방법 | 보폭 크기 개선 | keras.optimizers.RMSprop(lr = 0.001, rho = 0.9, epsilon = 1e - 08, decay = 0.0) |
| 아담(Adam) | 모멘텀과 알엠에스프롭 방법을 합친 방법 | 정확도와 보폭 크기 개선 | keras.optimizers.Adam(lr = 0.001, beta_1 = 0.9, beta_2 = 0.999, epsilon = 1e - 08, decay = 0.0) |
728x90
반응형
'ML | DL' 카테고리의 다른 글
| 머신러닝과 딥러닝 개념 총정리 (2) | 2025.06.17 |
|---|---|
| How does data sparsity affect your models? (0) | 2023.02.03 |
| [Interpolation] Interpolation (python) (0) | 2022.11.15 |
| [DNN] DNN, Forward / Back Propagation (순전파 / 역전파) (0) | 2022.11.07 |
| [분류] 1. 로지스틱 회귀분석 (0) | 2022.08.10 |