
RAG에서의 첫번째 단계 "Query" 다루기를 더 자세히 살펴보자.
질문 입력 및 변환 → 검색 및 재정렬 → 프롬프트 템플릿설정 → 문맥 구성 → 답변 생성 및 응답 제
1. Query 추론
내가 말하는 추론 단계는 Query를 정확하게 이해하는 단계이다. Query가 애매하거나 multi-hop 과정을 거쳐야 하는 경우
1-1. Query 재작성
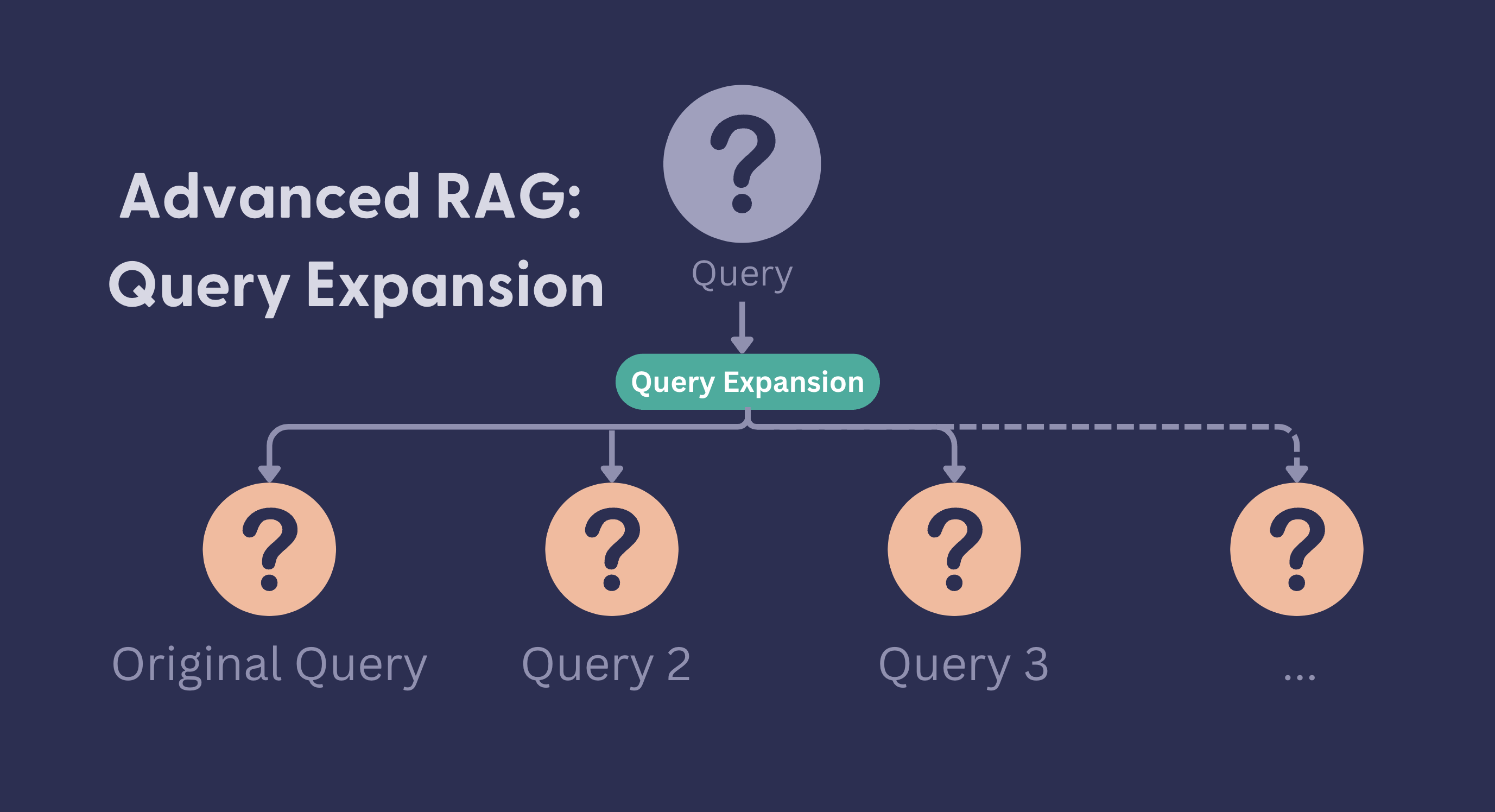
- LLM 활용하여 의미 추론 및 재구성
- 다중 질의 생성(multiquery generation): 질의 변형의 한 기법으로, 사용자의 원래 질문을 바탕으로 여러 개의 다양한 쿼리ㅡㄹㄹ 생성하는 방법
- 다중 질의 생성: LLM을 사용하여 원래 질문을 다양한 관점으로 변형시켜 여러 개의 질문 생성. 동의어 사용, 질문 구조 변경, 특정 측면 강조
- 병렬 검색: 생성된 각 쿼리를 사용하여 독립적으로 문서 검색
- 결과 통합
- 가상 문서 임베딩: 기존 쿼리에 대해 가사으이 문서를 만들어서 이를 쿼리 대신 활용하는 방법으로, 질문에 대한 '답변'을 기반으로 문서를 찾는 방식
1-2. multi-hop
- LLM 활용
2. 임베딩
문장이나 텍스트의 '문맥적 의미'를 저차원 밀집 벡터로 변환
- 임베딩을 하는 이유: 컴퓨터는 본질적으로 숫자 연산 장치이므로, 텍스트 자체로는 계싼하거나 패턴을 찾기 어렵다. 인간의 언어(텍스트)를 컴퓨터가 계산하고, 비교하고, 학습할 수 있는 숫자 형태(주로 벡터)로 변환해야 합니다.
- 주요 단계
토큰화(Tokenization): 분석 목적에 맞게 의미를 가진 최소 단위로 텍스트 분해벡터화(Vectorization): 분해된 단위를 숫자 벡터로 표현임베딩(Embedding)
2-1. 토큰화
- 단어 토큰화: 주로 공백, 구두점을 기준으로 분리. 한국어는 조사, 어미 분리가 불가해서 부적합할 수 있음.
- 형태소 토큰화: 의미를 가진 가장 작은 단위(형태소)로 분리(한국어 같은 교착어 처리에 필수적)
- 서브워드 토큰화: 단어를 더 작은 의미 단위로 분리.
- BPF (Byte-Pair Encoding, WordPiece(BERT), SentencPiece(다국어 지원)
- OOV(Out-of-Vocabulary) 문제 완화: 사전에 없는 단어도 subword 조합으로 표현 가능, 회귀 단어 처리, 형태학적 정보 부분적 반영
2-2. 벡터화/임베딩 선택 목적에 따라
- 간단 분석/키워드 추출 → TF-IDF
- 의미 기반 유사도 계산, 분류, 검색 → 임베딩 (Word2Vec, BERT, OpenAI 등)
2-3. 임베딩
- 단어, 문장 등의 텍스트 단위를 저차원의 연속적인 밀집 벡터로 변환하는 벡터화 기법. 벡터 공간에서 의미/문맥적 유사성이 벡터 간의 거리/방향으로 표현
- 단순 빈도를 넘어, 텍스트의 잠재된 의미를 벡터 공간에 투영
- 잠재 단어 임베딩(Static Word Embedding)
- Word2Vec
- 문맥적 임베딩(Contextual Embedding)
- ELMo, BERT, OpenAI Embeddings
- Transformer 아키텍쳐 기반의 거대 언어 모델 활용
Last Updated. 2025.06.09
🔖 참고 자료
728x90
반응형
'NLP | LLM' 카테고리의 다른 글
| 로컬 환경에서 필수인 Ollama에 대해 알아보기 (3) | 2025.06.18 |
|---|---|
| AI Agent의 모든 것 (5) | 2025.06.17 |
| [LangChain] 1. LangChain의 모든 것 (3) | 2025.06.17 |
| [RAG] 1. LangGraph의 등장과 동작과정 (0) | 2025.06.10 |
| [Text Summarization] 1. TextRank (0) | 2022.10.17 |